It is great when search engines frequently visit your site and index your content but often there are cases when indexing parts of your online content is not what you want. For instance, if you have two versions of a page (one for viewing in the browser and one for printing), you'd rather have the printing version excluded from crawling, otherwise you
risk being imposed a duplicate content penalty. Also, if you happen to have sensitive data on your site that you do not want the world to see, you will also prefer that search engines do not index these pages (although in this case the only sure way for not indexing sensitive data is to keep it offline on a separate machine). Additionally, if you want to save some bandwidth by excluding images, stylesheets and javascript from indexing, you also need a way to tell
spiders to keep away from these items.
One way to tell search engines which files and folders on your Web site to avoid is with the use of the Robots metatag. But since not all search engines read metatags, the Robots matatag can simply go unnoticed. A better way to inform search engines about your will is to use a robots.txt file.
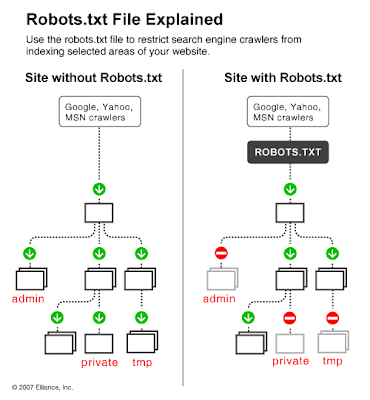
Robots.txt is a text (not html) file you put on your site to tell search robots which pages you would like them not to visit. Robots.txt is by no means mandatory for search engines but generally search engines obey what they are asked not to do. It is important to clarify that robots.txt is not a way from preventing search engines from crawling your site and the fact that you put a robots.txt file is something like putting a note “Please, do not enter” on an unlocked door – e.g. you cannot prevent thieves from coming in but the good guys will not open to door and enter. That is why we say that if you have really sen sitive data, it is too naïve to rely on robots.txt to protect it from being indexed and displayed in search results.
The location of robots.txt is very important. It must be in the main directory because otherwise user agents (
search engines) will not be able to find it – they do not search the whole site for a file named robots.txt. Instead, they look first in the main directory and if they don't find it there, they simply assume that this site does not have a robots.txt file and therefore they index everything they find along the way. So, if you don't put robots.txt in the right place, do not be surprised that search engines index your whole site.
The concept and structure of robots.txt has been developed more than a decade ago and if you are interested to learn more about it, visit or you can go straight to the Standard for Robot Exclusion because in this article we will deal only with the most important aspects of a robots.txt file. Next we will continue with the structure a robots.txt file.
The structure of a robots.txt is pretty simple (and barely flexible) – it is an endless list of user agents and disallowed files and directories. Basically, the syntax is as follows:
User-agent:
Disallow:
“User-agent” are search engines' crawlers and disallow: lists the files and directories to be excluded from indexing. In addition to “user-agent:” and “disallow:” entries, you can include comment lines – just put the # sign at the beginning of the line:
# All user agents are disallowed to see the /temp directory.
User-agent: *
Disallow: /temp/
The Traps of a Robots.txt File
when you start making complicated files – i.e. you decide to allow different user agents access to different directories – problems can start, if you do not pay special attention to the traps of a robots.txt file. Common mistakes include typos and contradicting directives. Typos are misspelled user-agents, directories, missing colons after User-agent and Disallow, etc. Typos can be tricky to find but in some cases validation tools help.
The more serious problem is with logical errors. For instance:
User-agent: *
Disallow: /temp/
User-agent: Googlebot
Disallow: /images/
Disallow: /temp/
Disallow: /cgi-bin/
The above example is from a robots.txt that allows all agents to access everything on the site except the /temp directory. Up to here it is fine but later on there is another record that specifies more restrictive terms for Googlebot. When Googlebot starts reading robots.txt, it will see that all user agents (including Googlebot itself) are allowed to all folders except /temp/. This is enough for Googlebot to know, so it will not read the file to the end and will index everything except /temp/ - including /images/ and /cgi-bin/, which you think you have told it not to touch. You see, the structure of a robots.txt file is simple but still serious mistakes can be made easily.
Tools to Generate and Validate a Robots.txt File
Having in mind the simple syntax of a robots.txt file, you can always read it to see if everything is OK but it is much easier to use a validator, like this one: http://tool.motoricerca.info/robots-checker.phtml. These tools report about common mistakes like missing slashes or colons, which if not detected compromise your efforts. For instance, if you have typed:
user agent: *
Disallow: /temp/
this is wrong because there is no slash between “user” and “agent” and the syntax is incorrect.
In those cases, when you have a complex robots.txt file – i.e. you give different instructions to different user agents or you have a long list of directories and subdirectories to exclude, writing the file manually can be a real pain. But do not worry – there are tools that will generate the file for you. What is more, there are visual tools that allow to point and select which files and folders are to be excluded. But even if you do not feel like buying a graphical tool for robots.txt generation, there are online tools to assist you. For instance, the Server-Side Robots Generator offers a dropdown list of user agents and a text box for you to list the files you don't want indexed. Honestly, it is not much of a help, unless you want to set specific rules for different search engines because in any case it is up to you to type the list of directories but is more than nothing.

No comments:
Post a Comment